





TL;DR
- Cerberus, using state sharding and a 3-phase Byzantine Fault Tolerant consensus protocol, presents a promising solution for scalability and fault tolerance in distributed ledger systems, ensuring high throughput and data integrity.
- The system’s ability to partition data into shards enables parallel processing and improved scalability.
- The consensus protocol ensures proper transaction ordering and replication within each shard, and also maintains coherence across multiple shards.
- The effectiveness of Cerberus will be truly tested and validated through its real-world implementation and performance under diverse network conditions.
Introduction
Distributed ledger technology (DLT) has the potential to revolutionize the way we conduct transactions and exchange value. However, one of the biggest challenges facing DLT is scalability.
Fully-replicated consensus protocols, such as Bitcoin and Ethereum, require all nodes in the network to process and validate every transaction. This means that as the number of nodes in the network grows, the amount of time and resources required to process and validate transactions also increases. This can lead to slow transaction times and high transaction fees, which can limit the scalability of the network. For example, Bitcoin can only process around 7 transactions per second, while Ethereum can process around 15 transactions per second. This is a significant limitation when compared to traditional payment systems, such as Visa, which can process thousands of transactions per second.
To address this challenge, a novel approach called the Cerberus protocol has been proposed. Cerberus is a multi-shard protocol that aims to provide a practical and efficient approach to multi-shard transaction processing that can enable high-performance and scalable distributed ledgers. The goal of Cerberus is to reduce the coordination necessary for multi-shard ordering and execution of transactions, which can improve scalability and reduce overhead costs.
Understanding the Longest Chain and Byzantine Fault Tolerance Consensus Protocols
Consensus protocols are the heart of blockchain technology, driving its core attributes of transparency, security, and decentralization. Among the prominent consensus protocols are Longest Chain (Nakamoto consensus) and Byzantine Fault Tolerance (BFT). Each has its unique features and influences factors like liveness, safety, finality, and determinism in blockchain systems.
Longest Chain Protocol
The Longest Chain protocol, key to Bitcoin’s Nakamoto consensus, dictates that the blockchain with the most proof-of-work (the longest chain) is deemed the legitimate transaction ledger. This protocol is probabilistic, meaning finality— the irrevocability of transactions— grows more certain over time as more blocks are added.
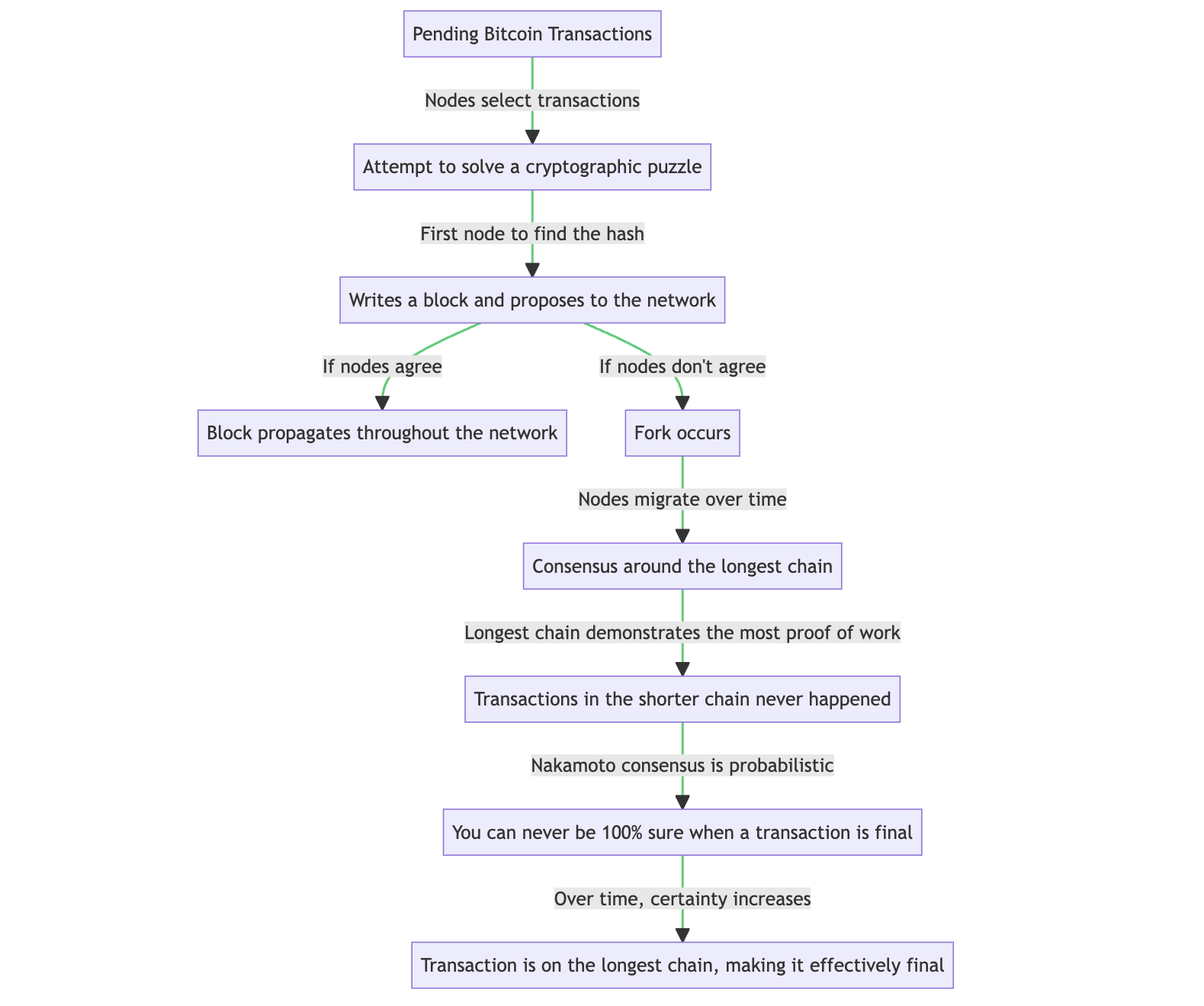
In the context of Ouroboros, the Longest Chain consensus concept takes on a slightly different form.
While the Longest Chain protocol in Bitcoin refers to the blockchain with the most accumulated proof-of-work, in Ouroboros, the protocol doesn’t rely on PoW. Instead, it operates based on the principle of staked interest. In Ouroboros, the right to create a block is determined by the proportion of cryptocurrency a participant has staked, not by their PoW efforts.
In this case, the “longest” chain doesn’t necessarily refer to the most work done, but rather to the chain that is adopted by the majority of stakeholder nodes. The slot leaders, selected based on their stake, add blocks to the chain. When multiple chains are present, the one that is backed by the highest total stake becomes the legitimate ledger.
These protocols assures high liveness, as any participating node can propose a block, and operations continue as long as mining is active. But it lacks immediate finality. Once a transaction is added to the chain, there’s a slim, but existent, chance it could be reversed in a chain reorganization. This potential trade-off illustrates the protocol’s resilience to Byzantine faults.
Byzantine Fault Tolerance (BFT) Protocol

On the other hand, Byzantine Fault Tolerance (BFT) protocols, such as Practical Byzantine Fault Tolerance (PBFT) and HotStuff, operate differently. BFT protocols guarantee system safety and function even if some nodes fail or behave maliciously, provided that the number of such nodes doesn’t exceed a specific limit.
One of BFT’s notable features is transaction finality. Once a transaction is logged, it’s irrevocable and permanent. This deterministic finality is a significant edge over the probabilistic finality of Longest Chain protocols. However, it compromises liveness as BFT requires more communication between nodes, potentially slowing down transaction processing.
What is Cerberus?
Cerberus, a minimalistic multi-shard Byzantine-resilient transaction processing protocol, is built on top of the Practical Byzantine Fault Tolerance (PBFT) consensus protocol.
PBFT is known for its high throughput and out-of-order processing capabilities, making it an ideal foundation for Cerberus. At the core of Cerberus lies a 3-phase Byzantine Fault Tolerant (BFT) consensus protocol that forms the core of the Cerberus multi-shard transaction processing system that aims to solve the State Machine Replication (SMR) problem.
What is the State Machine Replication (SMR) problem?
State Machine Replication (SMR) is a method used to maintain consistent states across distributed systems. At the heart of blockchain and distributed ledger technologies (DLT), SMR ensures that all nodes in the network agree on the state of the ledger. However, achieving effective SMR remains a critical challenge in designing scalable, robust, and secure DLT systems.
Understanding State Machine Replication (SMR)
SMR is a standard technique for implementing a fault-tolerant service by coordinating several servers to replicate the same service.
In the context of DLT, each node, or server, maintains a copy of the blockchain or ledger. The ledger acts as a state machine, where transactions are the inputs, and nodes must agree on the order of these transactions.
When a node receives a transaction, it adds the transaction to its version of the ledger, changing its state. Since all nodes follow the same set of rules for state changes, the states of all nodes should remain consistent if they all process the same transactions in the same order.
The Challenge
The inherent decentralization of DLT systems makes achieving effective SMR challenging. In centralized systems, a single authority determines the order of transactions, but in DLT, consensus must be reached among all nodes.
Scalability is another critical issue. As the number of participants in a network grows, the messaging overhead required to maintain consistency can significantly degrade system performance. Traditional consensus protocols, such as Paxos and Raft, were designed for small-scale systems, and their efficiency decreases as the system size increases.
Security is a third concern. The open and anonymous nature of many DLTs makes them vulnerable to Sybil attacks, where an attacker creates many pseudonymous identities. To thwart such attacks, DLTs need robust, Sybil-resistant consensus protocols, which further complicates the SMR process.
How does Cerberus solves the State Machine Replication (SMR) problem ?
Cerberus solves the State Machine Replication (SMR) problem through the use of state sharding. State sharding is a technique where the managed dataset is partitioned into multiple shards, and each shard operates as an independent blockchain or state machine.
In Cerberus, the system partitions the dataset across multiple shards, and each shard is responsible for processing a subset of the transactions. This partitioning allows for parallel processing and improves the scalability of the system. Each shard operates its own instance of the Cerberus consensus protocol, ensuring that transactions within each shard are ordered and replicated correctly.
To maintain consistency across shards, Cerberus employs cross-shard consistency mechanisms. When a transaction affects multiple shards, the protocol ensures that the necessary steps are taken in each shard to inform the client of the outcome. This cross-shard consistency guarantees that the client can reliably derive the true outcome of the transaction.
By utilizing state sharding, Cerberus achieves both scalability and fault tolerance. The system can process a higher volume of transactions by distributing the workload across multiple shards, and the replication of each shard ensures fault tolerance in case of failures or malicious behavior.
The Cerberus Consensus Protocol: An In-Depth Look
The Cerberus consensus protocol is a system designed to ensure the harmonious functioning of all nodes within a network. It operates on the basis of consensus, where all nodes agree on the order and validity of commands or transactions being added to the ledger.
The protocol is implemented in three distinct phases: the proposal phase, the validation phase, and the commit phase.

Phase 1: The Proposal Phase
The proposal phase initiates the process with a node in the network proposing a new command or transaction to be added to the ledger. This proposed command is represented as a vertex. Think of a vertex as a package that contains a new command or transaction that needs to be added to the ledger. It also includes a reference to the ‘parent vertex’, the last package that was added to the ledger. The proposing node then broadcasts the vertex to other nodes within the network.
Phase 2: The Validation Phase
Once the proposed vertex is broadcast, the validation phase begins. Here, each node within the network validates the proposed vertex in accordance with the rules of the DLT network. If validated, the node creates a quorum certificate (QC) – a digital signature that attests to the vertex’s validity. This QC includes the hash of the vertex and the hash of the QC of the parent vertex. Subsequently, the node sends the QC to other nodes in the network.
Phase 3: The Commit Phase
The final phase, known as the commit phase, involves all nodes agreeing collectively on the order and validity of the proposed vertex. This agreement is reached when a node receives QCs for the vertex from a two-thirds majority of the nodes. The receiving node then creates a new block that contains the vertex and QCs for all committed vertices since the last block. The new block is then broadcast to the other nodes. Upon receipt of the new block by a two-thirds majority of nodes, it is committed to the ledger.
Advanced Concepts: Sharding and Partially-Ordered Commands
One of Cerberus’ unique features is its implementation of a sharding technique for handling partially-ordered commands in a distributed ledger network. Sharding partitions the dataset into multiple shards, each functioning independently as a blockchain. This method facilitates the parallel processing of transactions across different shards, significantly improving the system’s overall throughput.
In conventional consensus-based designs, all transactions are fully replicated across the entire network. However, this leads to increased coordination and communication overhead and scalability issues as the number of participants and transactions grow.
By introducing sharding, Cerberus effectively addresses these limitations by handling a larger volume of transactions more efficiently.
Leveraging Partially-Ordered Commands: Enhancing Parallelism
The sharding technique employed by Cerberus allows the processing of partially-ordered commands within each shard. These are transactions without a strict total order, meaning they can be executed concurrently without conflict. This mechanism further enhances the system’s parallelism and throughput by allowing multiple transactions to be processed simultaneously within a shard.
By processing partially-ordered commands within partitioned datasets, Cerberus achieves a balance between scalability and consistency. It ensures that transactions within a shard are processed efficiently and in parallel, while maintaining the ledger’s integrity and correctness.
Cerberus’ Advanced Partitioning: Local and Emergent Cerberus Instances
Cerberus achieves consensus through advanced partitioning at the application layer. It combines multiple “local Cerberus” BFT instances to form an “emergent Cerberus” instance across shards. This results in parallelized emergent Cerberus instances across the shards. It combines optimistic concurrency control, multi-version concurrency control, two-phase commit protocols, and cross-shard exchange to achieve fault-tolerant and efficient transaction processing across multiple shards.

Local Cerberus Instances: Intra-shard Transactions
The Cerberus protocol is designed to handle transactions within a single shard through a combination of optimistic concurrency control and multi-version concurrency control. This is achieved through the use of Local Cerberus BFT instances, which are responsible for processing transactions within a single shard.
Optimistic concurrency control is a technique that allows multiple transactions to be processed concurrently, without explicit locking or blocking of the shard. This is achieved by allowing transactions to proceed optimistically, assuming that they will not conflict with other transactions. If a conflict does occur, the transaction is rolled back and retried.
Multi-version concurrency control is a technique that allows multiple versions of the same object to coexist in the shard, each representing a different state of the object. This allows transactions to proceed without blocking, even if they are accessing the same object. If a conflict does occur, the transaction is rolled back and retried with the latest version of the object.
Local Cerberus BFT instances are responsible for ensuring that transactions are processed correctly within a single shard. Each instance consists of a set of validator nodes that are responsible for processing transactions and reaching consensus on the current state of the shard. The validator nodes use a Byzantine fault-tolerant consensus algorithm to ensure that transactions are processed correctly, even in the presence of malicious actors or network failures.
When a transaction is submitted to a Local Cerberus BFT instance, it is first validated to ensure that it is well-formed and does not violate any constraints. If the transaction is valid, it is added to the shard’s transaction pool and processed concurrently with other transactions in the pool.

During processing, the transaction is executed against the current state of the shard, using optimistic concurrency control and multi-version concurrency control to ensure that it does not conflict with other transactions. If the transaction is successful, it is added to the shard’s transaction log and the state of the shard is updated accordingly.
If a conflict does occur, the transaction is rolled back and retried with the latest version of the object. This ensures that the transaction is processed correctly and that the state of the shard remains consistent.

In summary, Local Cerberus BFT instances are responsible for processing transactions within a single shard using a combination of optimistic concurrency control and multi-version concurrency control. This allows transactions to be processed concurrently without blocking, even if they are accessing the same object. The use of a Byzantine fault-tolerant consensus algorithm ensures that transactions are processed correctly, even in the presence of malicious actors or network failures.
Emergent Cerberus Instances: Inter-shard Transactions
In addition to Local Cerberus BFT instances, the Cerberus protocol also uses Emergent Cerberus instances to process transactions across multiple shards. Emergent Cerberus instances are responsible for coordinating transactions that involve objects in multiple shards, ensuring that the transactions are processed correctly and that the state of the ledger remains consistent.
To process transactions across multiple shards, Emergent Cerberus instances use a combination of two-phase commit protocols and cross-shard exchange. The two-phase commit protocol is used to ensure that all shards involved in the transaction agree to commit the transaction, while cross-shard exchange is used to exchange information between shards and ensure that the transaction is processed correctly.
When a transaction is submitted to an Emergent Cerberus instance, it is first validated to ensure that it is well-formed and does not violate any constraints. If the transaction is valid, the Emergent Cerberus instance creates a transaction proposal and sends it to all shards involved in the transaction.

Each shard then processes the transaction proposal using its Local Cerberus BFT instance, using optimistic concurrency control and multi-version concurrency control to ensure that the transaction does not conflict with other transactions in the shard. If the transaction is successful, the shard sends an acknowledgement back to the Emergent Cerberus instance.

Once all shards have acknowledged the transaction proposal, the Emergent Cerberus instance sends a commit request to all shards, using a two-phase commit protocol to ensure that all shards agree to commit the transaction. If all shards agree, the transaction is committed and the state of the ledger is updated accordingly.

If a conflict occurs during processing, the transaction is rolled back and retried with the latest version of the object. This ensures that the transaction is processed correctly and that the state of the ledger remains consistent.
In summary, Emergent Cerberus instances are responsible for coordinating transactions that involve objects in multiple shards, using a combination of two-phase commit protocols and cross-shard exchange to ensure that the transactions are processed correctly and that the state of the ledger remains consistent. The use of Local Cerberus BFT instances ensures that transactions are processed correctly within each shard, while the use of a Byzantine fault-tolerant consensus algorithm ensures that transactions are processed correctly across multiple shards, even in the presence of malicious actors or network failures.
Delineating Core, Optimistic, and Pessimistic Cerberus
The Cerberus system comes in three different versions – Core-Cerberus (CCerberus), Optimistic-Cerberus (OCerberus), and Pessimistic-Cerberus (PCerberus). Each version has its own strengths and is made to work best in specific situations.
CCerberus is the basic version. It needs a certain number of steps to agree on data for each piece of data, or shard, one step to share data between shards, and four steps of talking between parts of the system. This setup makes it good at processing transactions quickly, which is useful for situations like payment systems where speed is important.

OCerberus also needs the same number of agreement steps but takes three steps to share data and has three steps of talking between system parts. It’s designed to work well when there are not many transactions that conflict or overlap with each other, which means it can process transactions at the same time. Because of this, it’s great for situations where there’s a lot of activity and speed is important, like online marketplaces or gaming platforms.

PCerberus is a bit more complex. It needs twice as many agreement steps, one step to share data, and seven steps of talking between system parts. Like CCerberus, it’s also designed to be secure and reliable, especially when there are people trying to harm the system. This makes it good for situations where security is important, like financial systems or supply chain management systems that deal with sensitive information.

What happens when dishonest users change depending on the version. If there are no dishonest users, all transactions will go through. But if there are transactions happening at the same time that affect the same data, all versions will stop these transactions. After this, what happens changes depending on the version. CCerberus stops the reuse of the stopped transaction’s data, which might not work well in some situations. OCerberus might fail when trying to get everyone to agree on data and need to make changes in one or more shards. PCerberus stops these transactions normally, but it takes extra agreement steps.
All versions of Cerberus can handle dishonest replicas (Replicas are nodes in the distributed system that maintain a copy of the shared ledger and participate in the consensus protocol). Only dishonest primaries, can disrupt normal operations (Primaries are a specific type of nodes that is designated as the leader or coordinator for a particular shard.) If this happens, they’re noticed and replaced. CCerberus and PCerberus deal with a dishonest primary in a shard alone, while the failure of a primary in OCerberus can lead to changes in all shards affected by the transaction.

In terms of performance, all versions can handle more activity with more shards. Each version was tested with seven copies of data, or replicas, per shard and a bandwidth of 100 Mbit s−1 per replica. But it’s important to remember that with more shards, more shards are affected by each transaction, which means more agreement steps. This is especially true for big transactions that affect a lot of data.
Conclusion
In conclusion, Cerberus offers a promising approach to address the challenges of scalability and fault tolerance in distributed ledger systems. By leveraging state sharding and a 3-phase Byzantine Fault Tolerant consensus protocol, Cerberus demonstrates the potential to achieve high throughput and maintain the integrity of replicated state.
The strengths of Cerberus lie in its ability to partition data into shards, enabling parallel processing and improved scalability. The consensus protocol ensures that transactions within each shard are properly ordered and replicated, while cross-shard consistency mechanisms maintain coherence across shards. These features make Cerberus an appealing solution for environments with numerous shards, including permissionless networks.
However, it is important to acknowledge that the true test of Cerberus lies in its real-world implementation. Evaluating its performance, scalability, and resilience in practical scenarios with diverse network conditions and workloads will provide valuable insights. Real-world deployment will be instrumental in determining the effectiveness and identifying areas for improvement.



